CloudBroker in Practice: Scope, Stack, and Getting It Running #
Scope, limits, and how to run it.
We've covered the problem, the data, and the interface. This piece ties it up: scope (multiple providers, ingestion, recommendation API, optional analytics), what CloudBroker does not do (no provisioning, no Kubernetes, no real-time spot streaming), and how to get from clone to first recommendation.
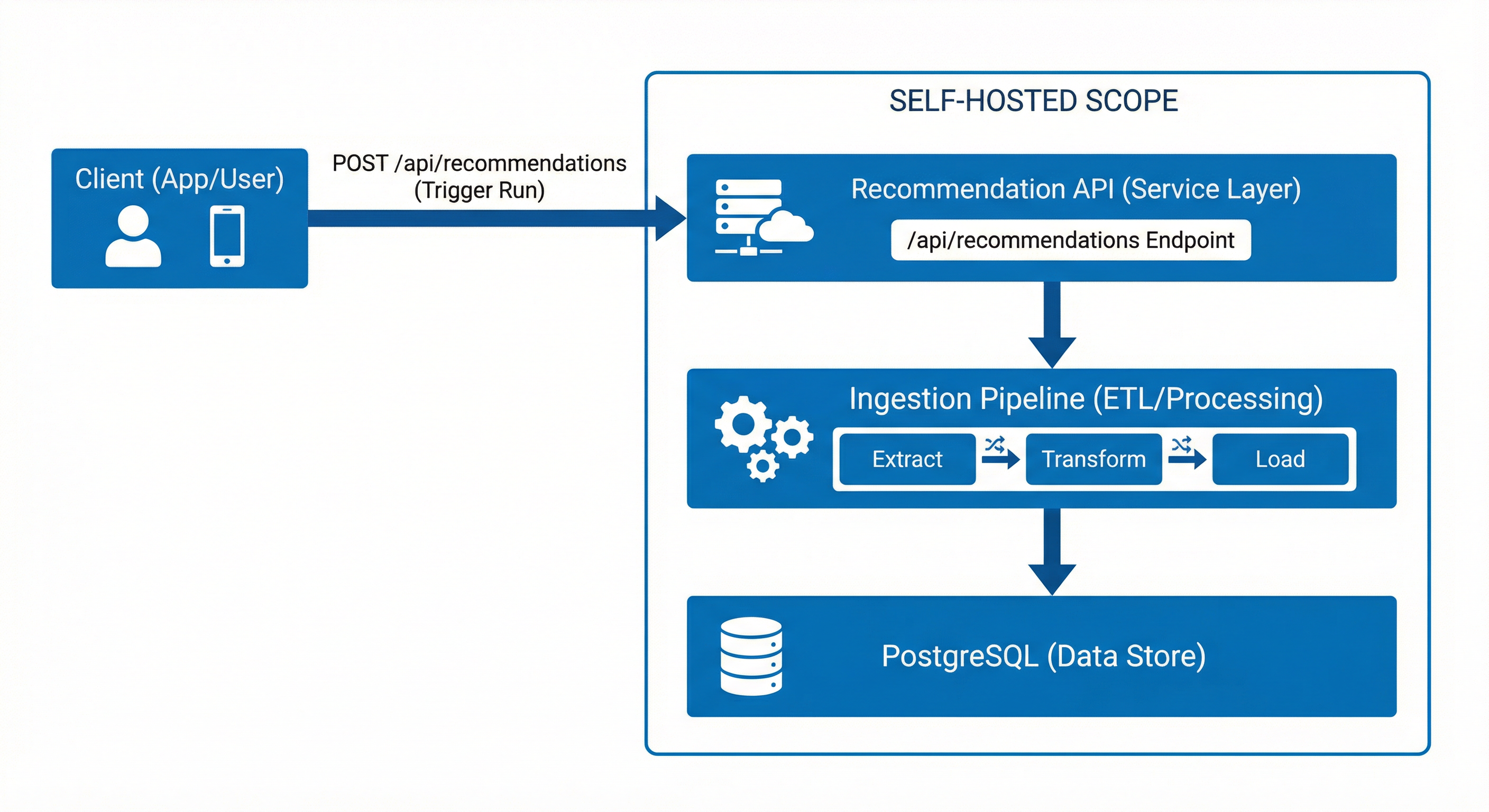
Scope recap
CloudBroker ingests instance types and hourly prices from multiple providers into one PostgreSQL database, normalized to EUR. It exposes a recommendation API: send constraints, get a ranked list. Optional price analytics endpoints (changes, trends) operate on the stored history. The API uses the last ingested snapshot — you control how often ingestion runs.
Out of scope (by design)
- No VM lifecycle — CloudBroker does not create or delete VMs.
- No cluster awareness — it doesn't know about Kubernetes or pods.
- Self-hosted — there is no SaaS offering in this project; you run it, you own the data and credentials.
- No non-compute products — focus is compute instance pricing for recommendation.
How to run it
- Clone the repo.
- Copy
.env.exampleto.envand set any required vars (e.g. DB URL, optional API key). - Start the stack:
make up(API + PostgreSQL). - Migrate:
make migrate. - Ingest for the providers you care about:
make ingest-hetzner,make ingest-gcp, ormake ingest-all. For TCO:make ingest-egressormake ingest-all-costs.
The API is available at http://localhost:8000; interactive docs at /docs. Any client can call POST /api/recommendations. For a Kubernetes controller that uses this API to provision burst nodes, see Cloudburst Autoscaler (separate project and docs).
Follow the step-by-step quickstart to get CloudBroker up in 5 minutes.
Go to Quickstart →Closing
CloudBroker is the place you ask "what's cheapest?" What you do with the answer — script, dashboard, or autoscaler — is up to you.